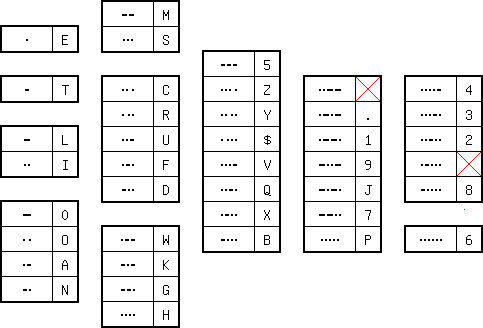
The following Morse codes are displayed here:
I know there have also been Hebrew, Arabic en Greek Morse code version, but I have not yet been able to ascertain the details.
This appears to be approximately the original Morse code. Dashes (when occurring singly) could be 2, 3 or 4 units long, moreover, double long spaces appeared in the original code. As far as I have been able to find, the code was organized a bit in the time each individual code took, I have made the display to reflect this. Note that for larger time slices not all possible codes are shown, those not shown did not occur. It appears that some additional, longer, codes were used, I do not show them yet.
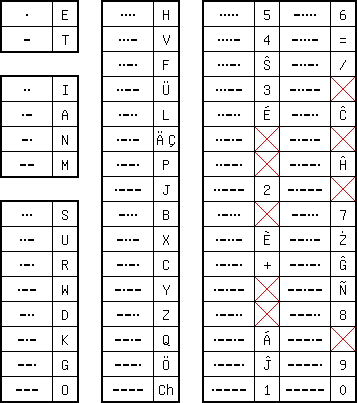
The table above shows
the world standard for Morse code. There is conflicting information,
especially about the accented letters. What is true is that now a dash
is (in time) three units (dots), the inter-letter spacing is also three
units, and the inter-word spacing is seven units. This table is
displayed with respect to the number of elements (dots and dashes)
involved. One to four units is for letters, five units is for digits
and some punctuation. Some codes there are used for accented letters,
but what I show here is probably incomplete. In most cases accented
letters map to letters with another accent, so all letters
U with an accent map
to the same character with a diaeresis. Also sometimes two accented
letters share the same code, as is shown above. And the combination
Ch (for Spanish)
shares the code with
S-cedilla (for other
languages). In all, this table appears to be Esperanto biased (and I
know that Esperanto morse has been standardized). Some of the codes
marked with a red cross are control codes and such, I have not yet been
able to ascertain exactly which is which.
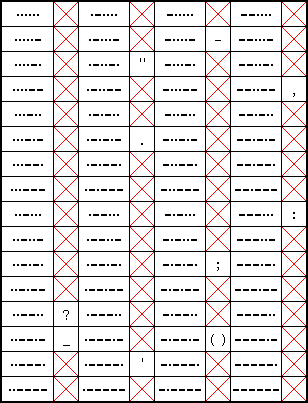
These are the six element codes of the Morse standard. Only a few of the positions are used, and all for punctuation. As above, there are some control codes, but I do not know them yet. Also it appears that some seven element codes have been defined, and even some eight element ones. More information about that might follow later.
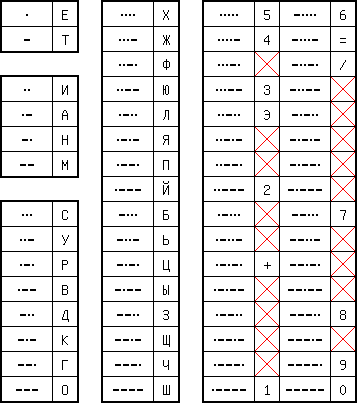
This is the Russian version of Morse. The Cyrillic letters are mapped to similar sounding or similar looking symbols in the Latin script. There is however one deviation from the (ASCII-look-alike) standardGOST 13052. The six element part of the table is not shown here, presumably it is the same as given above.
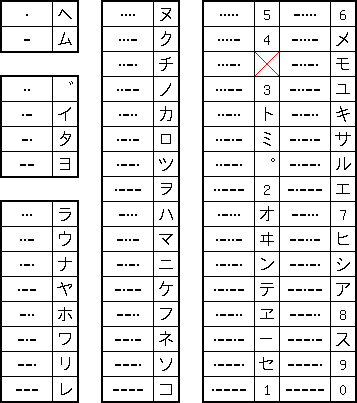
And here is the
Japanese Morse standard. It gives all full-size Katakana symbols as
present in JISCII (JIS X 201)plus the
additional
WE. These are not
part of JIS X 201 because they were removed from the Japanese
orthography after WW II. Here also the six element part is not shown. I
know the meaning of the single code marked with a red cross above, it
means "shift to world standard Morse".
WI and
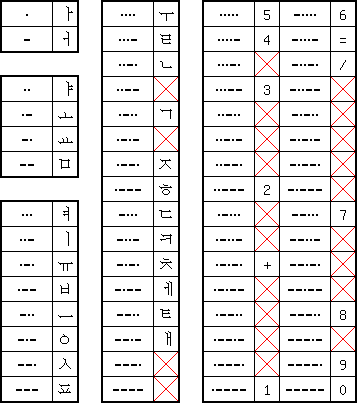
This shows the Korean Morse standard. In it codes are allocated to all Hangul consonants and vowels, plus two diphtongues. Contrary to other Hangul codes initial and final consonants are not distinguished.
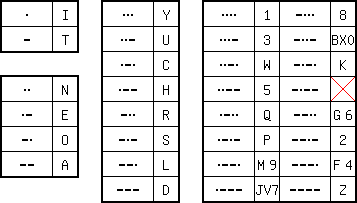
This shows the Morse code used for some time by the US Navy. Only one to four element codes are used. This means that in a number of cases symbols have to share a code, context should make clear what symbol is implied. This is shown in the table above by putting the symbols side by side.